
How Semantic Metadata Transforms Federated Analytics: An Expert Perspective
Having spent several years as an AI and Data Platform Architect, I’ve noticed that building federated analytics initiatives can feel a lot like organizing a family reunion—you desperately want everyone to get along, but the reality is a chaotic patchwork of conflicting personalities and potato salad recipes. Similarly, trying to harmonize analytics across decentralized teams, each with their own datasets, workflows, and definitions of a “customer,” feels eerily familiar.
The Dream vs. Reality: Federation is Here to Stay
When I first jumped into federated analytics, I carried grand visions like “One platform to rule them all.” Soon, though, I learned that federation isn’t just a buzzword—it’s the practical reality. Teams naturally evolve toward autonomy; domains diverge, and suddenly you’re navigating the analytics equivalent of independent city-states. This shift isn’t about compromise; it’s about recognizing scale.
The Metadata Blind Spot
Here’s where things get interesting: most architects (my younger self included) often overlook metadata, treating it like that dusty closet we promise ourselves we’ll clean someday. We focus obsessively on APIs and integrations—”Look, they all talk to each other!” But API-first metadata systems are like a room full of shouting toddlers: there’s a lot of noise, some communication, but little meaningful dialogue.
I learned this the hard way when our APIs beautifully integrated everything technically, yet my teams spent hours debating simple terms: What exactly counts as an “active customer” again? Semantic drift is a polite term for the heated debates and eye rolls that follow.
APIs are Great, but Graphs are Greater
API-based metadata architectures might be pragmatic at first—engineer-friendly and straightforward—but the cracks appear rapidly at scale. Over time, you notice that adding a new domain becomes as complicated as teaching your grandma TikTok. APIs give structure but miss out on shared meaning, leaving everyone speaking slightly different languages.
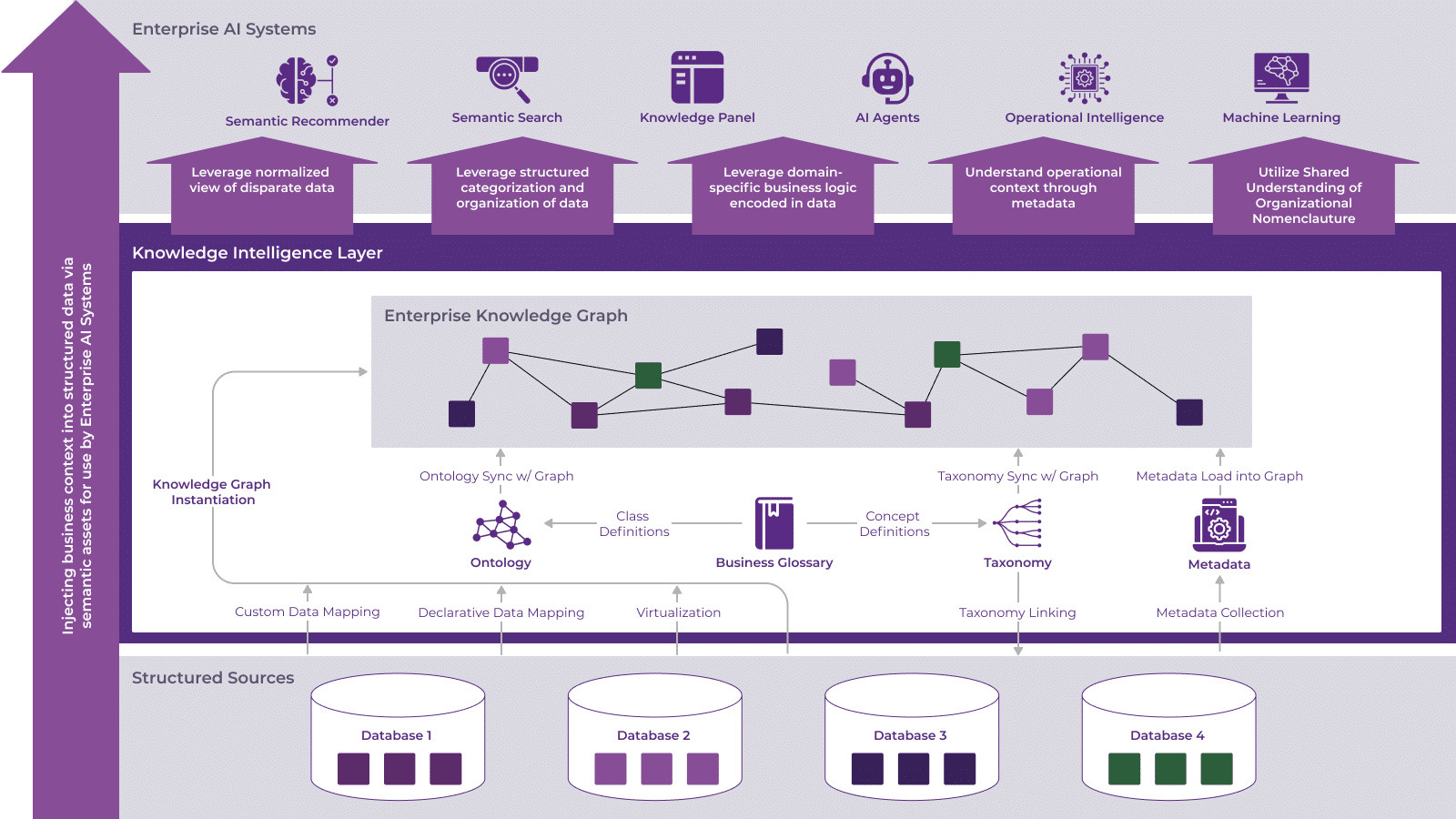
Enter the graph-based, semantic metadata approach. Adopting graph databases combined with open semantic standards such as RDF, OWL, SKOS, and SHACL was my architectural equivalent of discovering noise-cancelling headphones—finally, clarity! Graphs provide context, meaning, and crucially, the ability to reason across metadata. Now “customer” wasn’t just a term but a clearly defined semantic concept embedded with business logic and context.
Scaling Semantic Graphs for Big Enterprises
Scaling semantic graphs effectively for large enterprises involves defining clear, standardized ontologies and reusable data models. Leveraging industry-recognized semantic frameworks and best practices helps organizations structure common business concepts consistently. By adopting or customizing available open-standard ontologies, enterprises can align metadata across diverse teams, reduce semantic drift, and build a scalable metadata foundation as their data landscape grows.
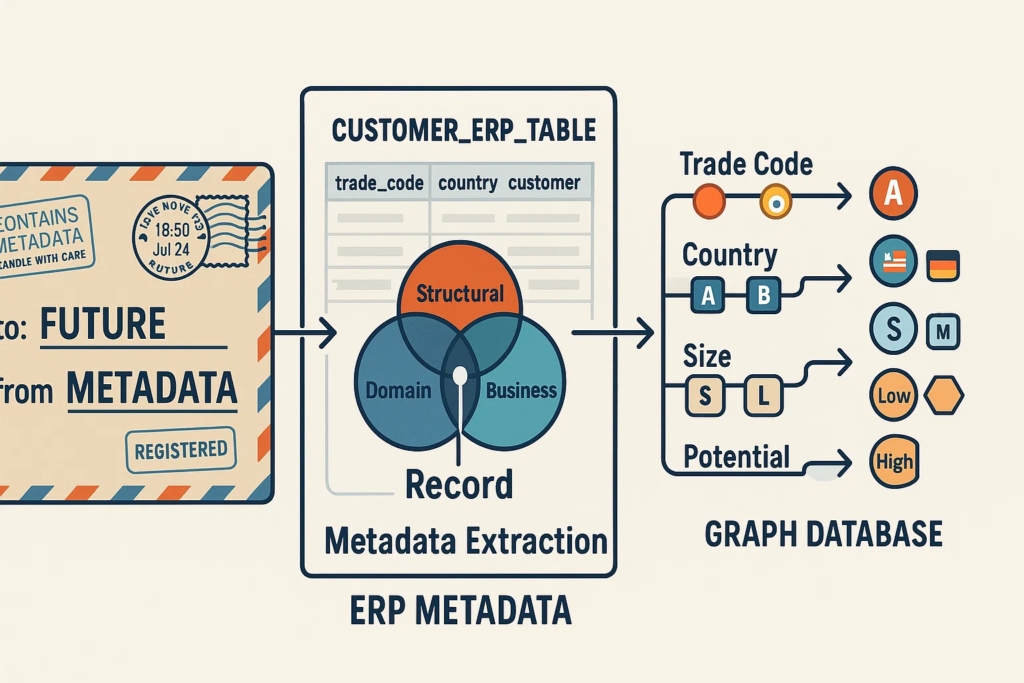
Example: Traditional Metadata vs. Graph-Based Approach
Consider a typical CRM system: a traditional metadata system captures basic fields—customer ID, name, purchase history. But these fields lack inherent context; they’re flat and isolated. A graph-based semantic approach, however, captures not only these fields but also their relationships and business rules—such as a customer’s contract status, privacy regulations applicable by jurisdiction, or account owner responsibilities. These relationships are explicit and machine-readable, enabling richer context and deeper insights across analytics platforms.
Understanding Semantic Context and Agentic AI
Semantic context refers to the detailed and structured meaning of metadata—definitions, relationships, constraints, and behaviors clearly represented in machine-readable formats. When implemented correctly, semantic context enables AI agents (agentic AI) to interpret business logic accurately, reason about data dependencies, and take informed actions. For example, an AI agent managing customer retention could automatically understand contractual terms and privacy constraints, ensuring compliance while optimizing engagement strategies.
Humor: An AI agent without good metadata context is like my Roomba without furniture awareness—constantly stuck, confidently confused.
Architecting for Agency, not Oversight
The real shift I noticed was when metadata architecture moved beyond governance checklists and into operational intelligence. Teams outside traditional data roles—think HR building onboarding assistants or finance teams crafting forecasting models—needed metadata they could trust without a degree in data engineering.
Graph-based semantics is a shared language. We can achieve federation without fragmentation and autonomy without chaos. Remember, metadata isn’t just plumbing; it is a strategic asset.
Wrapping Up (With a Friendly Warning)
If there’s one takeaway from my journey: don’t treat metadata like your leftover pizza—something forgotten in the fridge until it’s too late. Treat it as your enterprise’s nutritional plan: foundational, purposeful, and designed for long-term health.
Federation is inevitable, but chaos isn’t. Choose your metadata architecture wisely—your future AI and analytics capabilities depend on it.





Leave a Reply