
AWS S3 Tables & Apache Iceberg: The Future of Data Storage
Introduction
At AWS re:Invent 2024, AWS introduced Amazon S3 Tables, a purpose-built solution for managing tabular data at scale, built on the Apache Iceberg standard.
AWS S3 Tables represent a ground breaking approach to data management, built on the Apache Iceberg standard. By introducing a specialized S3 bucket type with native Iceberg support, AWS simplifies large-scale data storage and analytics, offering native support for ACID transactions, schema evolution, and time-travel queries. These tables enable seamless integration with AWS analytics services, providing 3x faster query performance and 10x higher transaction throughput compared to traditional S3 storage, while automating complex metadata management and performance optimization tasks that previously required significant engineering effort.

What is Open Table Format (OTF)?
Traditional databases require installing database software, creating databases, defining schemas, and setting up tables before data can be read. Open Table Format takes a different approach – data is stored directly in file formats like Apache Parquet, Apache ORC, or Apache Avro within a data lake. Instead of loading data into a traditional database, OTF creates virtual tables on top of file directories.
Query engines like Apache Spark, Trino, or AWS Athena can access these virtual tables through a catalog system such as AWS Glue Catalog. The most widely adopted open table formats are Apache Iceberg, Delta Lake, and Apache Hudi, known for their performance, scalability, and advanced features including time-travel queries and schema evolution.
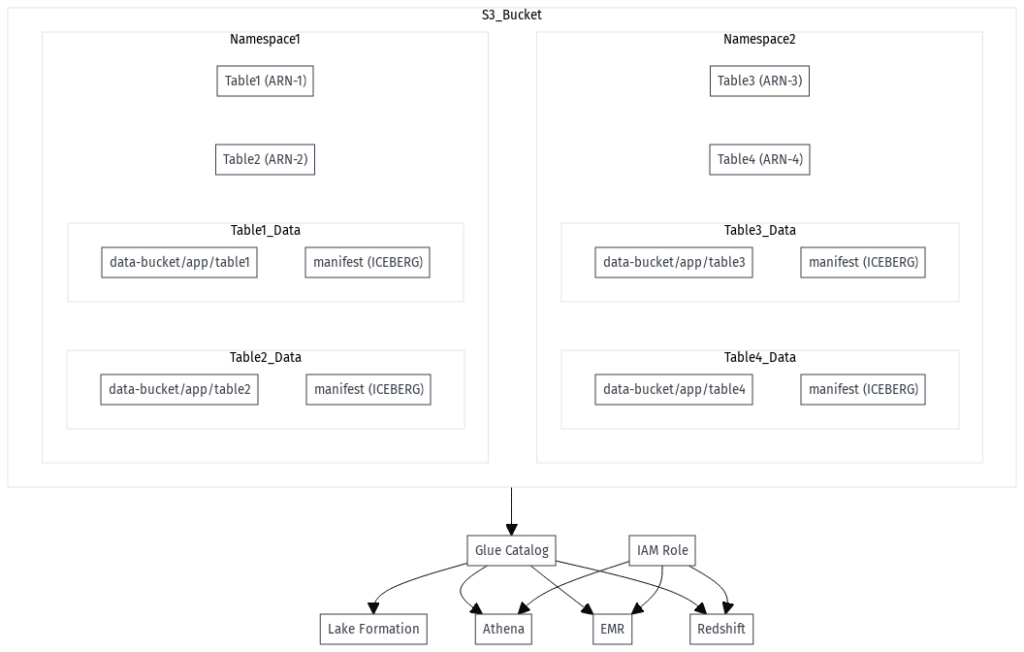
Apache Iceberg
Apache Iceberg is an open-source table format designed for large datasets in data lakes. It provides ACID transactions, schema evolution, and time-travel queries, making data lakes function more like traditional databases while maintaining reliability in cloud storage systems like AWS S3 (general purpose bucket type).
Prior to S3 Tables, AWS offered two bucket types: the original general purpose bucket and the directory bucket (introduced with S3 Express at re:Invent 2023). The directory bucket provides improved performance and hierarchical storage. At re:Invent 2024, AWS introduced the third type – Amazon S3 Table Bucket.
Core Value Proposition S3 Tables
- Performance Boosts (*ref)
- 3x faster query performance compared to standard S3
- 10x higher transaction throughput for high-volume workloads
- Automatic Maintenance
- Built-in processes for compaction, cleanup, and metadata optimization
- Native AWS Integration
- Seamless compatibility with Amazon Athena, EMR, Glue, and QuickSight
- Open Format Compatibility
- Support for Iceberg-compatible formats (e.g., Parquet)
- Accessibility for third-party query engines
2. Amazon S3 Tables Implementation
S3 Tables utilize a special bucket type called a table bucket, which organizes tables as sub resources. These buckets support Apache Iceberg format, enabling seamless data management and querying.
Creating S3 Table Resources
# Create s3 table bucket
aws s3control create-table-bucket \
--account-id <AWS_ACCOUNT_ID> \
--bucket-name data-bucket
# Create Amazon s3 table
aws s3control create-table \
--account-id <AWS_ACCOUNT_ID> \
--bucket-name my-table-bucket \
--table-name my_table \
--table-type ICEBERG \
--namespace namespace13. S3 Tables : FinOps
Storage Costs
- S3 Tables: $0.0265/GB/month
- Standard S3: $0.023/GB/month
Operational Costs
- $0.005 per 1,000 requests for data access and maintenance operations
- $0.05/GB processed for compaction
Sample Cost Scenario
For a typical setup with:
- Daily ETL job writing 1,000 small files (5 MB each)
- 1 TB total data size
- 500,000 GET requests per month
- Enabled automatic compaction
Monthly costs breakdown (US-West Oregon):
- Storage: $27.14 (1,024 GB × $0.0265/GB)
- PUT requests: $0.15 (30,090 requests)
- GET requests: $0.20 (500,000 requests)
- Monitoring: $0.26 (10,240 objects)
- Compaction: $7.62 (object and data processing)
Total Monthly Cost: $35.37
4. Automated Maintenance
S3 Tables offer fully managed maintenance through the PutTableMaintenanceConfiguration API:
{
"TableMaintenanceConfiguration": {
"Compaction": {
"Enabled": true,
"MaxFileSizeMB": 128,
"CompactionFrequencyHours": 24
},
"SnapshotRetention": {
"Enabled": true,
"MaxSnapshots": 5,
"RetentionPeriodDays": 30
},
"GarbageCollection": {
"Enabled": true,
"OrphanedFileRetentionDays": 7
}
}
}5. Access Control
5.1 Table Bucket Level Policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "AllowBucketAction",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/dataengineer"
},
"Action": [
"s3tables:GetTableMetadataLocation",
"s3tables:GetTableData",
"s3tables:ListTables",
"s3tables:GetTableMaintenanceConfig",
"s3tables:GetTableBucketMaintenanceConfig"
],
"Resource": "arn:aws:s3tables:us-east-1:123456789012:bucket/data-bucket/table/*"
}
]
}5.2 Table-Level Policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "AllowTableAction",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/dataengineer"
},
"Action": [
"s3tables:GetTableMetadataLocation",
"s3tables:GetTableData"
],
"Resource": "arn:aws:s3tables:us-east-1:123456789012:bucket/data-bucket/table/table-UUID"
}
]
}5.3 Namespace Level Policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "AllowTableAction",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/dataengineer"
},
"Action": [
"s3tables:GetTableMetadataLocation",
"s3tables:GetTableData"
],
"Resource": "arn:aws:s3tables:us-east-1:123456789012:bucket/data-bucket/table/*",
"Condition": {
"StringLike": {
"s3tables:namespace": "namespace1"
}
}
}
]
}6. Risks and Considerations Against S3 Tables
Cost Considerations
- High-frequency real-time workloads could incur significant costs
- A pipeline processing 1 PB/month with compaction could cost ~$60,000/day
- Small file-intensive operations may lead to unexpected costs
Vendor Lock-in Considerations
- Reliance on AWS-managed services creates partial vendor dependency
- Migration to other Iceberg-compatible storage systems may not replicate all features
- AWS-native optimizations may complicate vendor switching
Evaluation Strategy
- Audit current Iceberg use cases and estimate S3 Table costs
- Pilot S3 Tables on a small scale before production deployment
- Implement governance and monitoring framework
- Balance managed simplicity with specific requirements
7. AWS S3 Tables Impact on the Data Ecosystem
From my experience, Amazon S3 Tables has potential to transform the modern data architecture landscape by addressing key challenges in data lake management. The introduction of native Iceberg support within S3 fundamentally changes how organizations can build and scale their data platforms.
By providing automated maintenance, enhanced performance, and seamless integration with AWS analytics services, S3 Tables bridge the gap between traditional data warehouses and data lakes. This convergence enables organizations to maintain the flexibility of open formats while enjoying the performance and manageability typically associated with proprietary systems.
The impact on the competitive landscape is significant:
Databricks and Delta Lake
The native integration of Iceberg in S3 Tables challenges Databricks’ Delta Lake dominance by offering similar capabilities without requiring additional software layers. Organizations can now implement lakehouse architectures directly within their AWS infrastructure, potentially reducing the need for separate specialized platforms.
Snowflake and Data Warehousing
While Snowflake maintains its position in the data warehouse space, S3 Tables enhance hybrid architectures where Snowflake accesses external data through Iceberg tables. This complementary relationship enables organizations to optimize their data stack based on specific workload requirements rather than platform limitations.
Future Data Architecture & S3 Tables
S3 Tables enable several architectural advantages:
- Simplified ETL pipelines with direct writing to optimized storage
- Encourage data federation between systems
- Enhanced query performance without sacrificing data lake flexibility
- Cost-effective scaling for growing datasets
- Streamlined integration with both AWS and third-party analytics tools
This combination of features positions S3 Tables as a catalyst for broader Iceberg adoption, particularly among organizations seeking to modernize their data infrastructure while maintaining cloud-native principles and open standards.
S3 Tables Future Implications
- Increased demand for Iceberg-compatible tooling
- Further innovation in query engines and optimization
- Evolution of cost models for real-time workloads
Conclusion
AWS S3 Tables represent a significant advancement in managing and querying large-scale data, combining open format flexibility with managed service benefits. While they offer impressive performance gains and automated maintenance, organizations must carefully evaluate costs and integration requirements, particularly for real-time workloads. The service positions AWS strongly in the open table format landscape while potentially reshaping how organizations approach data lake architecture.
In addition, I also talked about how to efficiently manage storage in data platform here.







Leave a Reply