
Beyond Traditional Data Engineering: Your Guide to Emerging Specializations
Introduction
In today’s data-driven world, the field of data engineering has evolved far beyond its initial scope. What was once a relatively straightforward role focused on building data pipelines has transformed into a diverse spectrum of specializations, each requiring unique skill sets and expertise. In this blog, I talk about the various shades of data engineering roles that exist in modern organizations.
To understand these roles better, we first need to comprehend the sophisticated architecture that modern data platforms are built upon.
- Ingestion layer.
- Storage layer
- Processing layer
- Exposition layer
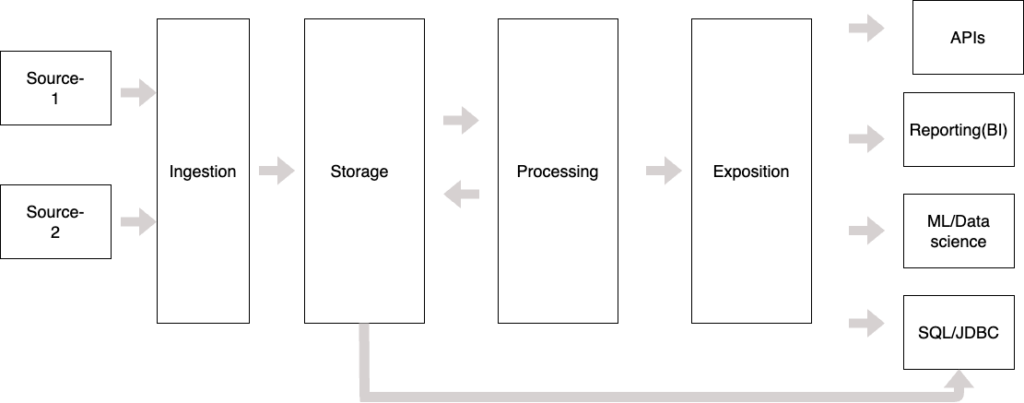
1. Ingestion Layer
This layer handles data acquisition from various sources and is divided into two main components:
- Batch Ingestion: Handles periodic data loads from sources like databases, files, and APIs
- Streaming Ingestion: Processes real-time data from sources like IoT devices, user interactions, and live transactions (Events)
2. Storage Layer
Modern data platforms implement a dual-storage strategy:
- Fast Storage: Optimized for quick access and real-time processing (e.g., in-memory databases, SSDs)
- Slow Storage: Designed for cost-effective storage of large volumes of historical data (e.g., data lakes, object storage)
3. Processing Layer
This critical layer transforms raw data into valuable insights:
- Batch Processing: Handles large volumes of historical data
- Stream Processing: Processes real-time data for immediate insights (processing events with Kafka / event bus etc..)
- Hybrid Processing: Combines both approaches for lambda or batch architectures, I like to call it as mini-batch processing
4. Metadata Layer
A newer but crucial addition to modern architectures:
- Data Catalog: Documents data assets and their relationships
- Lineage Tracking: Monitors data flow and transformations
- Quality Metrics: Tracks data quality and reliability
- Access Controls: Manages data governance and security
5. Exposition Layer
Delivers processed data to various consumers:
- Data Warehouses: For traditional business intelligence
- Data Marts: For department-specific analytics
- Feature Stores: For machine learning applications
- APIs: For application integration
- Real-time Services: For immediate data access (Event driven approach)
6. Orchestration Layer
Coordinates and manages the entire data flow:
- Workflow Management: Schedules and monitors data pipelines
- Resource Management: Optimizes compute and storage resources
- Error Handling: Manages failures and retries
- Monitoring: Tracks system health and performance
Data engineers must understand how these layers interact and the trade-offs involved in different architectural decisions. This layered approach helps organizations manage complexity, scale effectively, and deliver value from their data assets.
Now let’s talk about categories of Data Engineering, I will talk about their importance and different skill set requires.
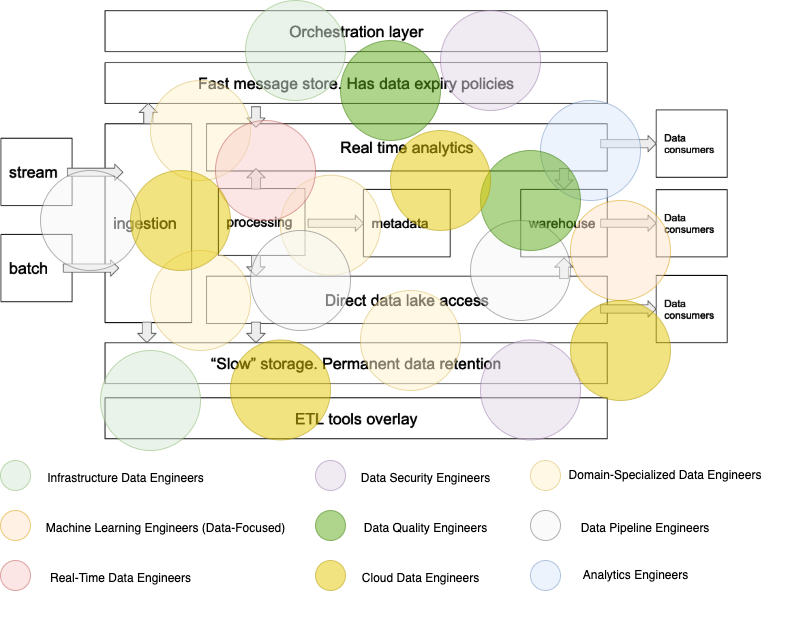
Domain-Specialized Data Engineers
Perhaps one of the most valuable yet often overlooked roles in data engineering is the Domain-Specialized Data Engineer. These professionals stand out for their deep understanding of business contexts and data meaning rather than just technical expertise. Their key strengths include:
- Deep business domain knowledge in specific industries (finance, healthcare, retail, etc.)
- Strong understanding of data lineage and business context behind each data point
- Ability to translate business requirements into effective data solutions
- Expert knowledge of business metrics, KPIs, and reporting requirements
- Skills in data quality assessment from a business perspective
While they may not be experts in cutting-edge technologies like Spark or complex infrastructure, they excel with fundamental tools:
- Proficient in SQL for data analysis and transformation
- Advanced Excel skills for business analysis
- Experience with business intelligence and reporting tools
- Basic understanding of data modeling from a business perspective
Their value comes from:
- Acting as a bridge between technical teams and business stakeholders
- Ability to spot data anomalies that might be missed by purely technical validation
- Understanding the impact of data changes on business processes
- Providing context and meaning to raw data
- Ensuring data solutions truly meet business needs
Data Pipeline Engineers
At the foundation of data engineering lies the Pipeline Engineer. These professionals are the architects of data movement, focusing on:
Their primary responsibility is ensuring data flows smoothly from source systems to destinations while maintaining data quality and performance. They work extensively with ETL/ELT tools, scheduling frameworks, and monitoring systems to ensure reliable data delivery.
Pipeline Engineers must deeply understand concepts like data partitioning, incremental loading, and fault tolerance. Tools like Apache Airflow, dbt, and various cloud-native services are their daily companions.
Analytics Engineers
A relatively new but rapidly growing role, Analytics Engineers bridge the gap between data engineers and data analysts. They focus on:
Analytics Engineers typically work closely with business stakeholders to understand reporting needs and implement data models that serve these requirements. They’re experts in SQL and data modeling, often working with tools like dbt, Looker, or similar modern data stack components.
Infrastructure Data Engineers (DataOps)
These specialists focus on building and maintaining the foundational data infrastructure that supports all data operations. Their responsibilities include:
They work with technologies like Kubernetes, Terraform, and various cloud services to create scalable, reliable data platforms. Strong DevOps knowledge and system design skills are crucial for this role.
Machine Learning Engineers (Data-Focused)
While distinct from traditional ML Engineers, these specialists focus on the data engineering aspects of machine learning operations:
They build robust data pipelines specifically for ML applications, working with technologies like feature stores, ML metadata management systems, and model serving infrastructure.
Real-Time Data Engineers
As businesses increasingly require real-time insights, Real-Time Data Engineers have become essential. They specialize in:
These engineers work with streaming technologies like Apache Kafka, Apache Flink, or Apache Spark Streaming to build systems that can process and analyze data in real-time.
Data Quality Engineers
With the growing importance of data quality, some engineers specifically focus on ensuring data reliability:
They implement data quality checks, monitoring systems, and data testing frameworks. Tools like Great Expectations, dbt tests, and custom validation frameworks are part of their toolkit.
Cloud Data Engineers
While cloud knowledge is important for all data engineers, Cloud Data Engineers specifically excel at:
They have deep expertise in specific cloud platforms (AWS, GCP, Azure) and their data services, often holding multiple cloud certifications.
Data Security Engineers
With increasing data privacy regulations and security concerns, Data Security Engineers focus on:
They work closely with security teams to implement encryption, access controls, and audit mechanisms for data systems.
Conclusion
The field of data engineering continues to evolve and specialize. While many data engineers wear multiple hats, especially in smaller organizations, larger companies often have dedicated roles for each specialization. The addition of Domain-Specialized Data Engineers highlights that technical expertise alone is not enough – deep business understanding and domain knowledge are equally crucial for delivering valuable data solutions.
As the field continues to mature, we may see even more specializations emerge, particularly around areas like data governance, DataOps, and industry-specific data engineering roles. The key to success in any of these roles remains the same: a strong foundation in data engineering principles, combined with specialized knowledge in specific areas of focus, whether that’s technical expertise or domain knowledge.






Leave a Reply